こんにちは。植松です。
OCRという言葉、聞いたことがありますか?
OCRとは「光学文字認識」といって、紙文書をスキャナーで読み込み、書かれている文字を認識してデジタル化する技術です。(Optical Character Reader(またはRecognition)の略)
PDFやPNGなどに書かれている文字をメモ帳(テキストエディタ)やWordなどに手作業で転記、もしくは、紙に書き出してたことはありませんか?
そういった手間をOCRによって自動化が可能です。
OCRを提供するサービスはいくつもあります。今回はAWSが提供している「Amazon Textract」を試してみようと思います。
私自身、OCRを使ったことが無いのでどれくらいの精度で文字を認識するのか楽しみです。
Amazon Textractについて
実際に試す前に、「Amazon Textract」について確認しました。
Amazon Textract は、スキャンしたドキュメントからテキスト、手書き文字、レイアウト要素、データを自動的に抽出する機械学習 (ML) サービスです。単純な光学文字認識 (OCR) のレベルにとどまらず、ドキュメントから特定のデータを識別、理解、抽出します。
Amazon Textract は ML を利用して、手作業なしで、あらゆる種類のドキュメントを読み取って処理し、テキスト、手書き文字、表などのデータを正確に抽出します。
参考:https://aws.amazon.com/jp/textract/
どんな画像データでもいい感じに読み取ってくれるようですね。
Amazon Textract は、現時点では PNG、JPEG、TIFF、および PDF 形式をサポートしています。
参考:https://aws.amazon.com/jp/textract/faqs/
一般的に使われるファイル形式がサポートされていますね。
Amazon Textract は現在、米国東部 (バージニア北部)、米国東部 (オハイオ)、米国西部 (オレゴン)、米国西部 (北カリフォルニア)、AWS GovCloud (米国西部)、AWS GovCloud (米国東部)、カナダ (中部)、欧州 (アイルランド)、欧州 (ロンドン)、欧州 (フランクフルト)、欧州 (パリ)、アジアパシフィック (シンガポール)、アジアパシフィック (シドニー)、アジアパシフィック (ソウル)、およびアジアパシフィック (ムンバイ) の、各リージョンで利用いただけます。
東京・大阪リージョンには現時点では未対応のようです。
Amazon Textract は、英語、ドイツ語、フランス語、スペイン語、イタリア語、ポルトガル語で印刷されたテキスト、フォーム、表を抽出することができます。
日本語がない。。。もしかして読み取れない??
実験1:英文(PNG形式)
まずは英文を読み取ってみようと思います。
用意したのは、外務省のHPに記載の記事をスクリーンショットしPNG形式にしたものです。

このPNGをTextractに読み込ませてみます。
さっそくマネージメントコンソールからTextractを開いてみます。
すると、この画面が出ました。東京リージョンではTextractが使えないので、別のリージョンを選択するようにということですね。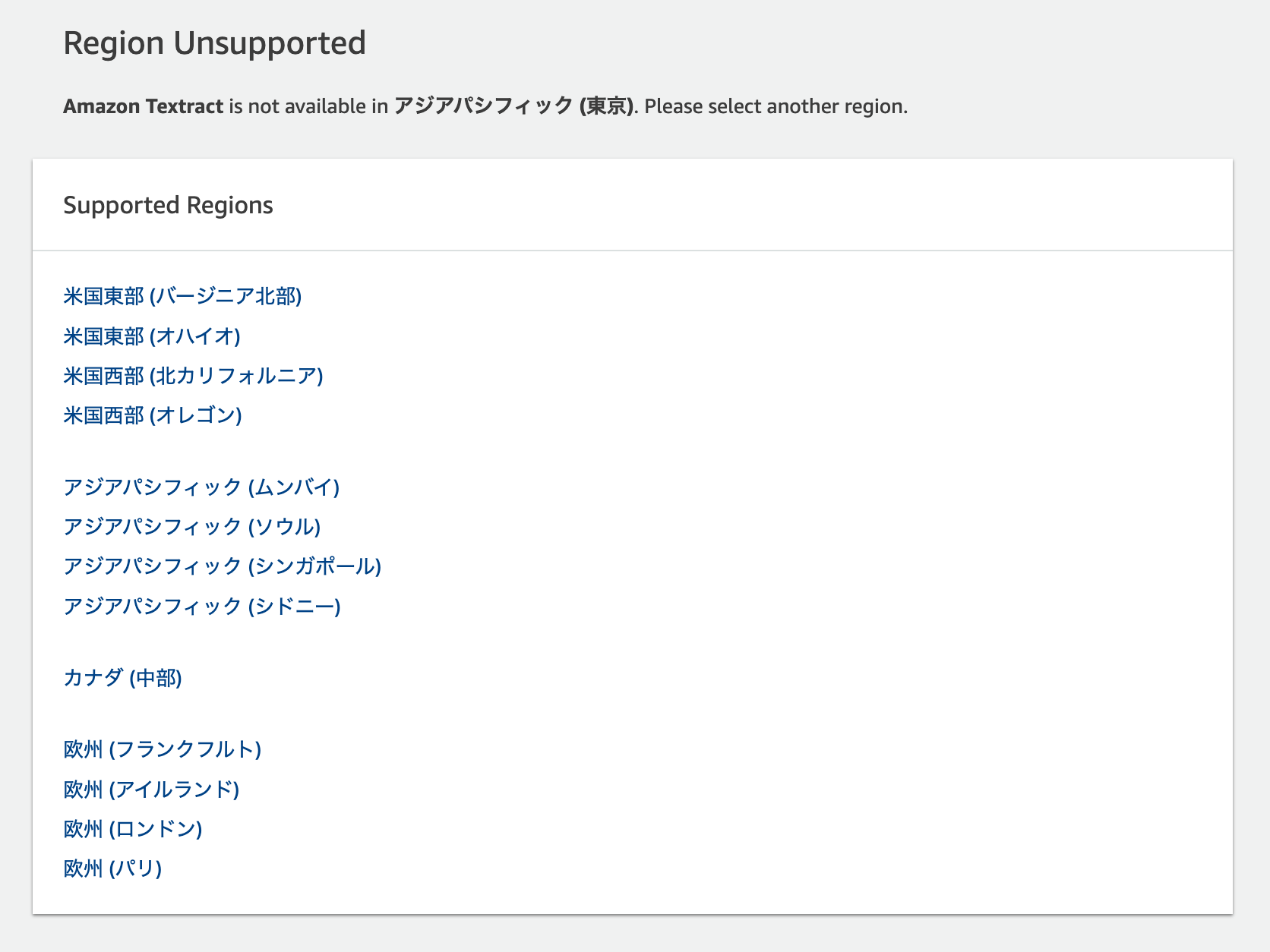 今回はバージニア北部を選択しました。
今回はバージニア北部を選択しました。
「Amazon Textract を試す」を押します。
直接ファイルをアップすることが可能なようですので、アップしてみます。 結果。いい感じに読み取ってくれていそうです。
結果。いい感じに読み取ってくれていそうです。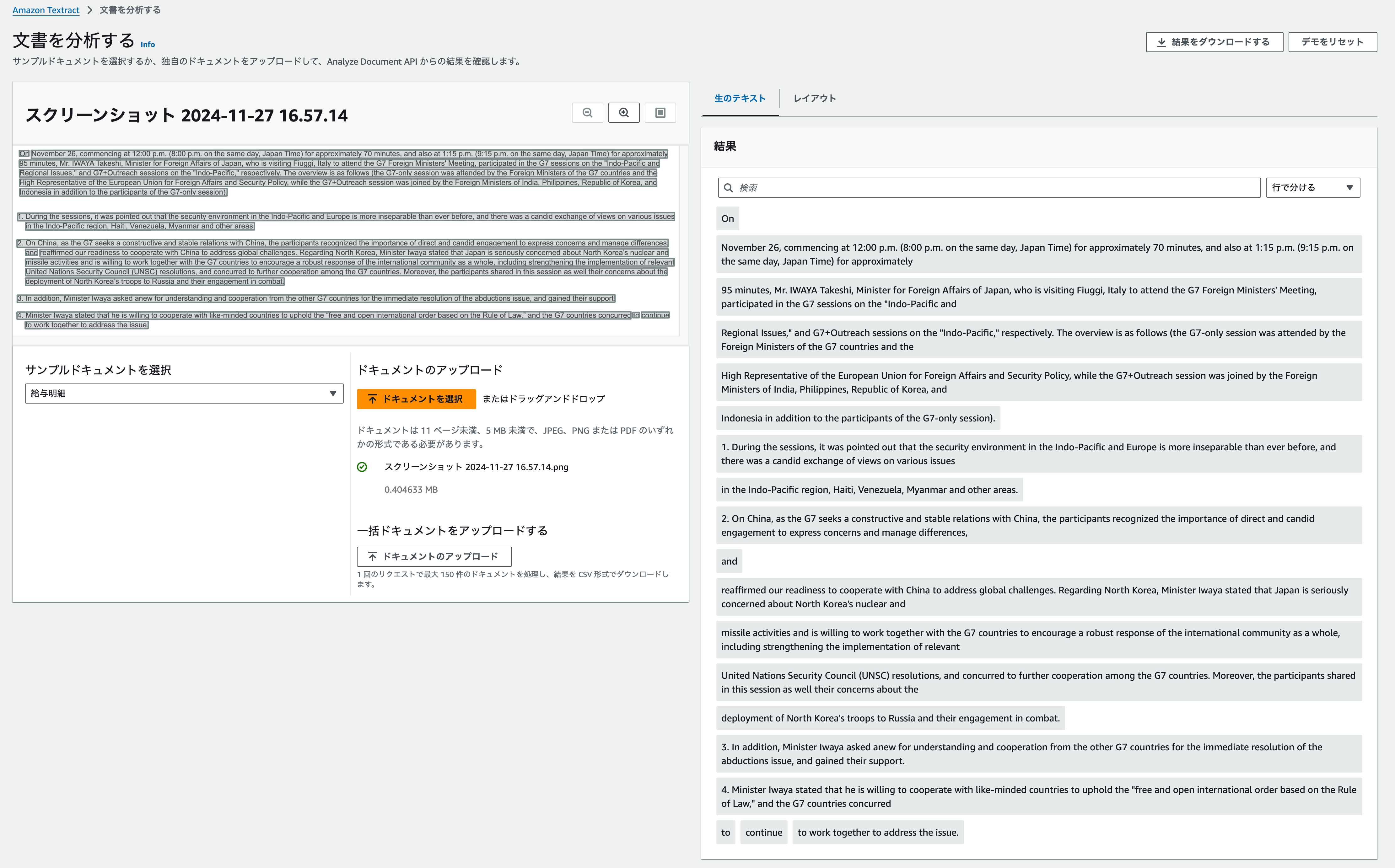 左が読み込んだ画像、右が文字起こしされたテキストです。
左が読み込んだ画像、右が文字起こしされたテキストです。
実験2:英文(PDF形式)
次は実験1で使った記事を一回Wordにコピーして、PDF形式でエクスポートしたものをアップしてみました。
結果、読み込み自体行われませんでした。なぜ・・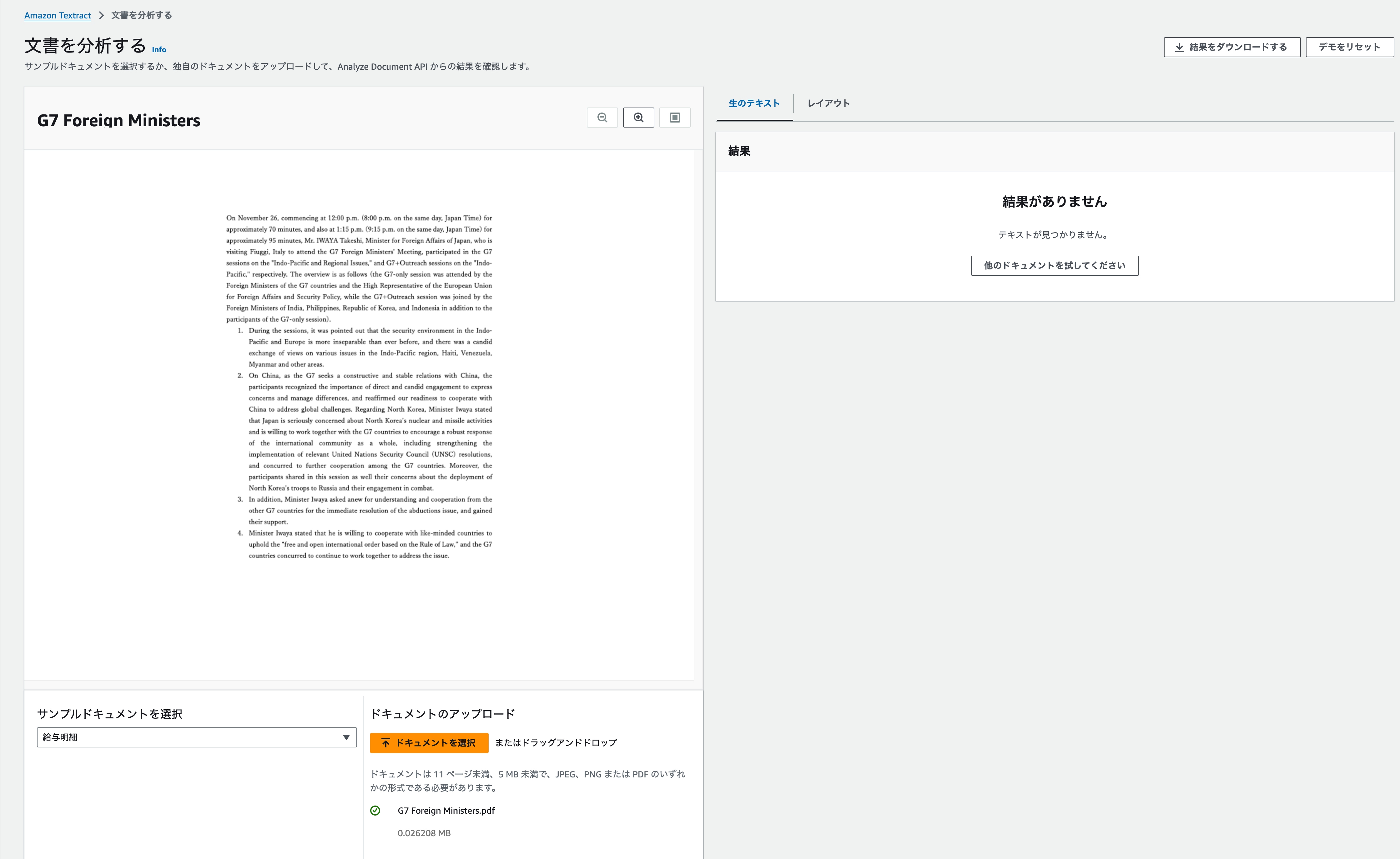 この後他にもPDF作っては読み込ませてみたのですが、全部↑でした。何かやり方が悪いのだろうか。。。
この後他にもPDF作っては読み込ませてみたのですが、全部↑でした。何かやり方が悪いのだろうか。。。
このPDFをPNGにしたら、実験1と同じように読み込んでくれました。PDFの作り方が悪かったのか??
実験3:英文・表組みあり(PNG形式)
次は表組みのある英文を読み込ませてみます。こちらの記事も外務省からスクショを撮りました。
結果、いい感じに読み取っているようです。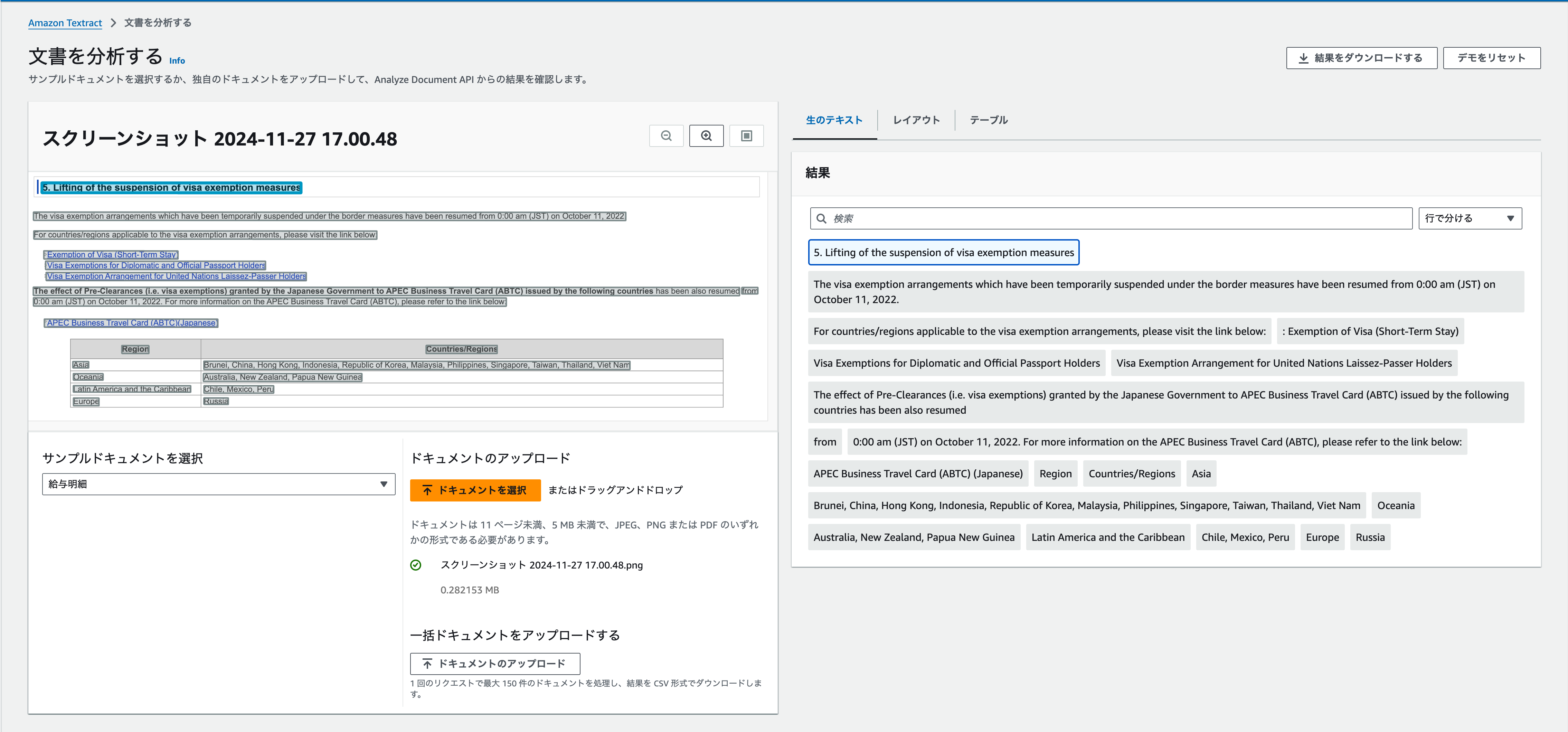
テーブルもこの通り。認識しています。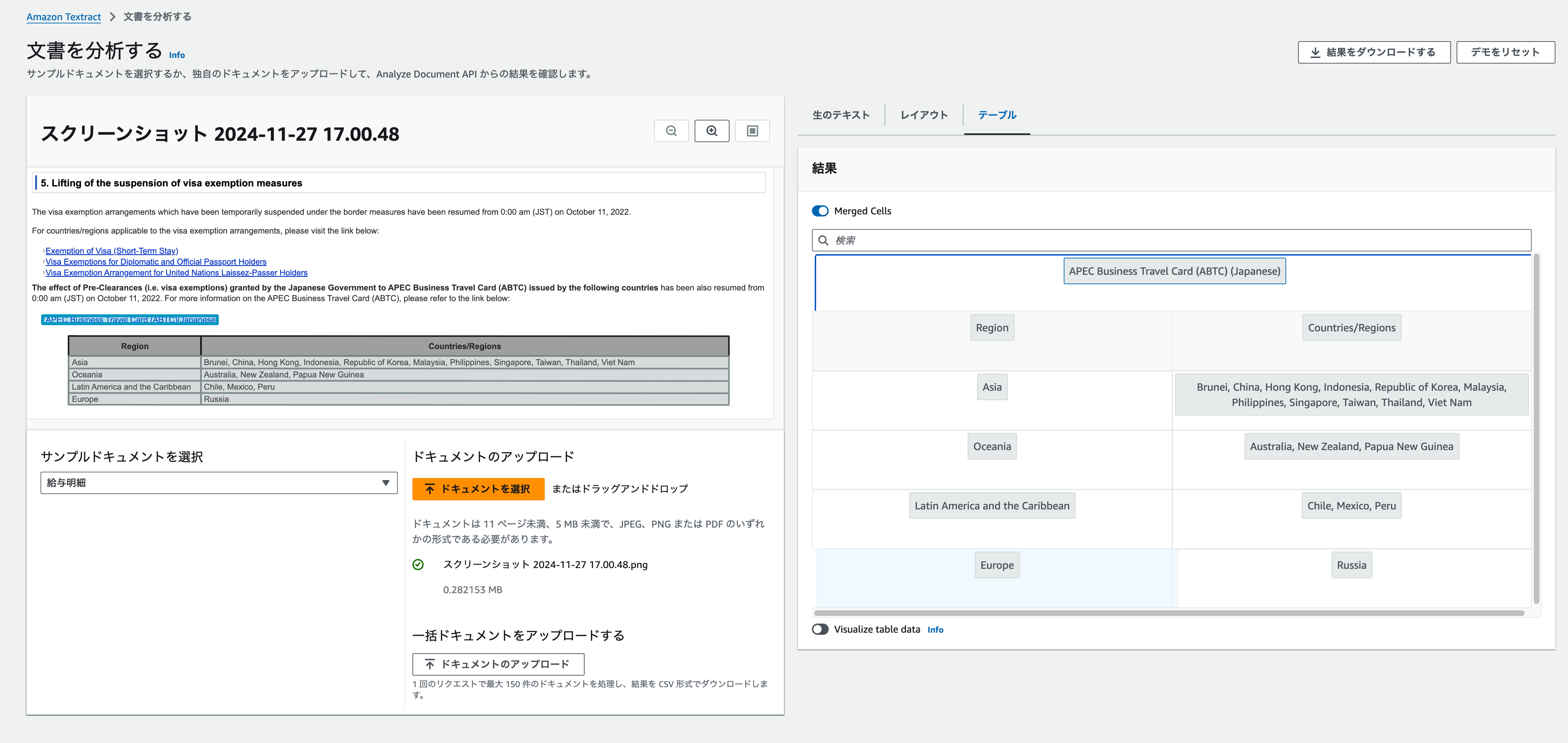
実験4:日本語文(PNG)
次はいよいよ日本語文です。首相官邸のHPに記載のあった記事をスクショし、アップ。
結果、日本語は全く認識してくれませんでした。。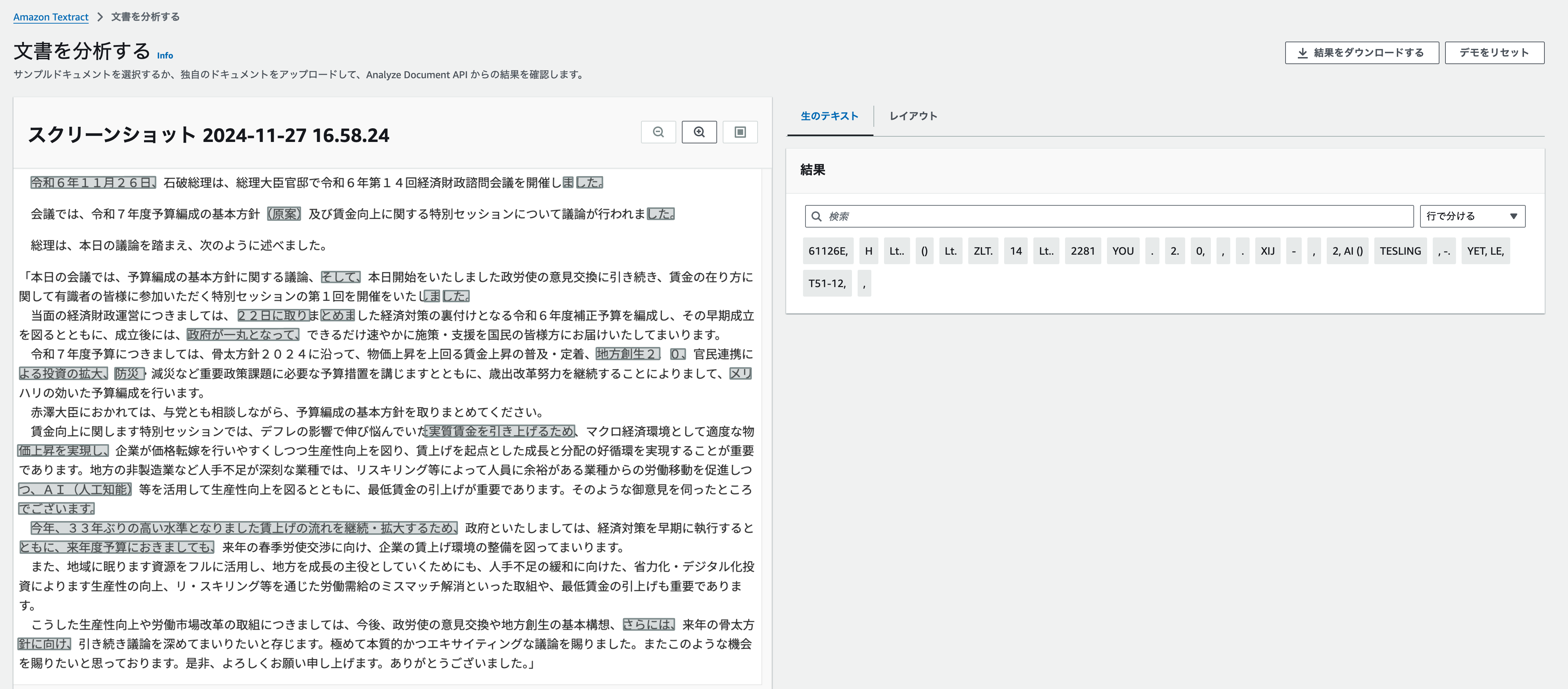 最初に確認したときから不安はあったのですが、やはり現時点では日本語に対応してないようです。
最初に確認したときから不安はあったのですが、やはり現時点では日本語に対応してないようです。
おわりに
今回はAWS Textractを試してみました。日本語を取り扱う場合には選択肢からは外れる(現時点では)ということがわかってよかったです。
ただ、英文の読み込み精度はほぼ完璧に近い(あくまでも体感です)ので、利用ケースは十分あると思います。
いつの日か日本語に対応してくれることを期待しましょう。