こんにちは。植松です。
AWSを利用していると必ずと言っていいほど使っているサービス、S3。S3も色々種類があって何を使えばいいのかわからない、、、
今回はS3についてまとめようと思います。
注:執筆時点での料金体系となっています。S3ご利用の際は公式ページを必ずご確認ください。
S3ストレージクラス一覧
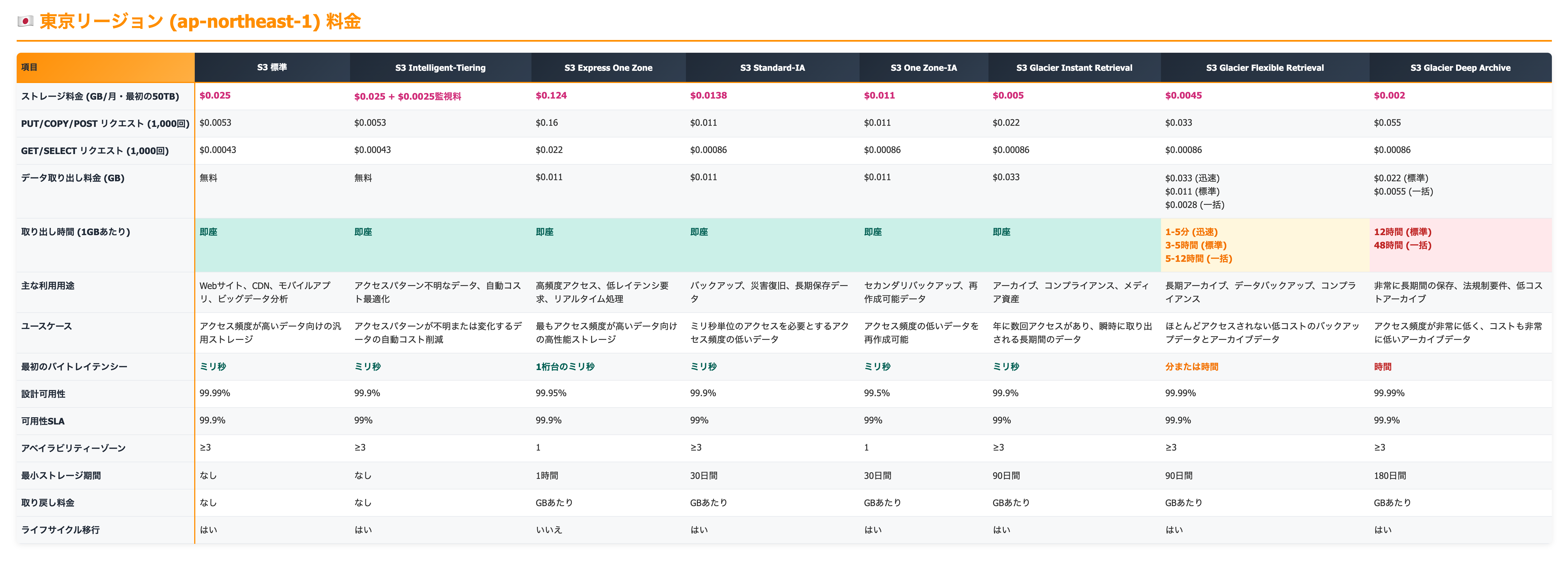
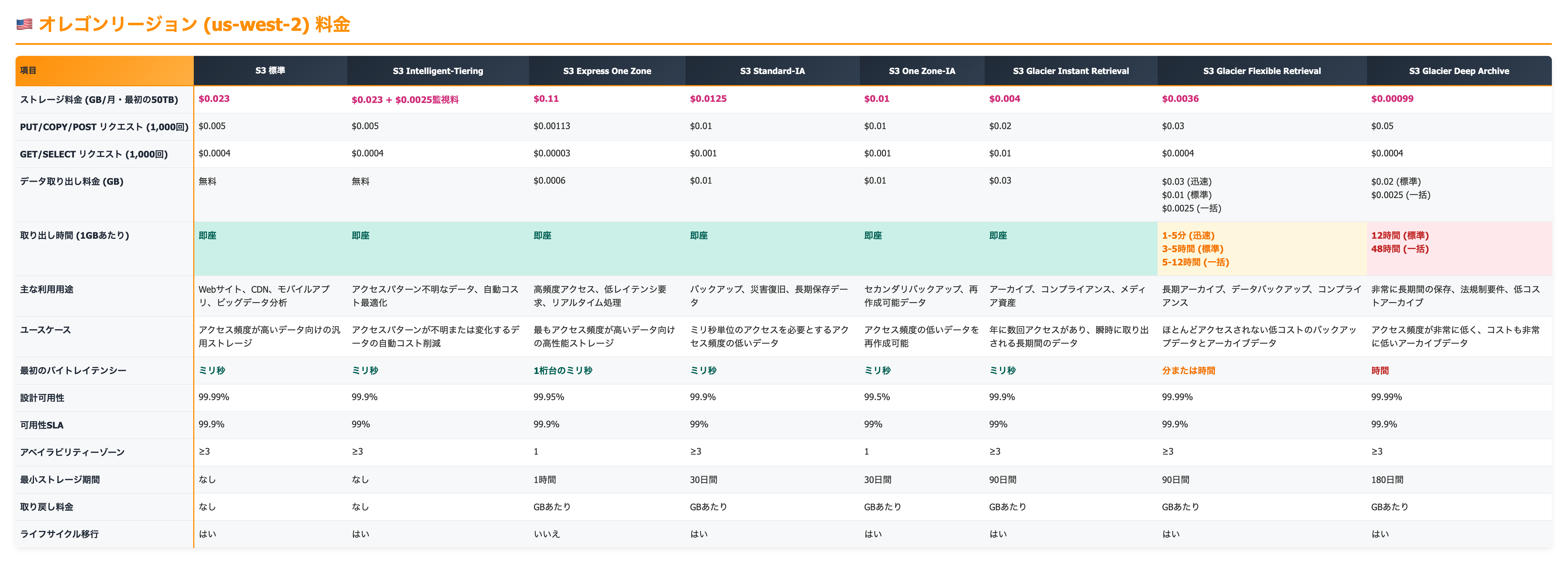
項目について
各項目が何を意味するのかを理解しておきましょう。
1. ストレージ料金 (GB/月・最初の50TB)
これは、S3にデータを保存しておくために月々かかる料金です。データ量(ギガバイト:GB)あたりで計算されます。
- 「最初の50TB」:S3の料金は、保存しているデータ量が増えるにつれて、1GBあたりの単価が安くなる「段階料金」になっていることが多いです。この項目は、最初の50TBまでのデータに対する1GBあたりの単価を示しています。
- ポイント: データ保存の基本料金です。安いほどお得ですが、他の料金(リクエスト料金や取り出し料金)とのバランスが重要です。
2. PUT/COPY/POST リクエスト (1,000回)
S3にデータを「書き込む」「コピーする」「アップロードする」といった操作を行う際にかかる料金です。1,000回あたりの単価で表示されています。
- PUT: 新しいファイルをS3にアップロードしたり、既存のファイルを新しい内容で上書きしたりする時に発生します。
- COPY: S3にあるファイルを別の場所にコピーする時に発生します。
- POST: ウェブサイトなどから直接S3にファイルをアップロードする際に使われる操作です。
- ポイント: 頻繁にファイルをS3にアップロードしたり更新したりするシステムでは、この料金が無視できません。
3. GET/SELECT リクエスト (1,000回)
S3に保存されているデータを「読み出す」「取得する」といった操作を行う際にかかる料金です。こちらも1,000回あたりの単価で表示されています。
- GET: S3からファイルをダウンロードしたり、ウェブサイトでS3にある画像を表示したりする時に発生する、最も一般的な読み出し操作です。
- SELECT: S3に保存されたデータ(ログファイルなど)の中から、必要な情報だけを「検索して取り出す」際に発生する特別な読み出し操作です。
- ポイント: ウェブサイトの画像や動画など、ユーザーが頻繁にアクセスするデータでは、このリクエスト料金が大きくなることがあります。
4. データ取り出し料金 (GB)
S3からデータをダウンロードする際に、そのデータ量(ギガバイト:GB)に応じてかかる料金です。
- ポイント: 特に「低頻度アクセス」や「アーカイブ」向けのストレージクラスで重要になります。これらのクラスは、保存料金は安いですが、データを取り出す際に追加で料金がかかることが多いです。倉庫に預けた荷物を取り出す際にかかる手数料のようなイメージです。
5. 取り出し時間 (1GBあたり)
S3からデータを取り出すまでにかかる時間です。
- ポイント: 数ミリ秒で取り出せるものから、数時間から数日かかるものまで様々です。すぐにデータが必要な場合は「即座」なクラスを、緊急性が低いアーカイブデータなら時間がかかっても安いクラスを選ぶ、というように使い分けます。
6. 主な利用用途 / ユースケース
それぞれのストレージクラスが、どのような種類のデータやシステムに適しているかを示しています。
- ポイント: これが最も重要な選択基準の一つです。データがどんな使われ方をするかによって、最適なクラスは変わります。
7. 最初のバイトレイテンシー
データをリクエストしてから、最初のデータが届くまでの時間(遅延)です。
- ポイント: 「ミリ秒(ms)」であればほぼ一瞬、「分」や「時間」であれば待つ必要があります。ウェブサイトの表示など、応答速度が重要な場合は「ミリ秒」である必要があります。
8. 設計可用性 / 可用性SLA
- 設計可用性: そのストレージクラスが、AWSの設計上どれくらいの頻度でデータにアクセスできる状態にあるかを示す数値です。例えば「99.999999999% (イレブンナイン)」といった非常に高い数値がS3の標準です。これはデータの耐久性(データが失われにくいか)と密接に関わります。
- 可用性SLA: AWSが、サービスが稼働していることを保証する割合(%)です。もしこのSLAを下回った場合、AWSからクレジット(料金の割引)が提供されることがあります。
- ポイント: サービスが停止しにくいか、データが失われにくいかを示す重要な指標です。
9. アベイラビリティーゾーン (AZ)
データが最低何箇所(アベイラビリティーゾーン)に分散して保存されるかを示します。アベイラビリティーゾーンとは、AWSのデータセンターの物理的に独立した場所のことです。
- ポイント: 複数AZに保存されることで、あるAZに障害が発生してもデータが失われにくくなり、サービスの継続性が高まります。単一AZのクラスは、そのAZに問題が発生した場合、データが一時的にアクセスできなくなったり、失われたりするリスクがあります。
10. 最小ストレージ期間
S3に保存したデータを、最低どれくらいの期間保存しておく必要があるかというルールです。
- ポイント: この期間より早くデータを削除すると、残りの期間分の料金がペナルティとして発生します。例えば「30日間」のクラスで10日後に削除した場合、残りの20日分の料金が請求されます。
11. 取り戻し料金
これはデータ取り出し料金と同じ意味です。S3の文脈では「取り戻し料金(Retrieval Fee)」という言葉も使われます。
12. ライフサイクル移行
あるストレージクラスから、別のストレージクラスにデータを自動的に移動させる機能が使えるかどうかです。
- ポイント: 例えば、最初はアクセス頻度が高いのでS3 Standardに保存し、30日後にはアクセス頻度が下がると予想されるのでStandard-IAに自動的に移行させる、といった設定ができます。これにより、データの利用状況に応じて自動的にコストを最適化することが可能です。
各ストレージクラスの詳細解説
それでは、いよいよ各ストレージクラスの特徴と、どのようなデータに最適なのかを解説していきます。
1. S3 標準 (S3 Standard)
- 特徴: 最も一般的なS3のストレージクラスで、バランスの取れた性能とコストを提供します。
- こんなデータに: ウェブサイトのコンテンツ、モバイルアプリのデータ、頻繁にアクセスするビッグデータ分析、CDN (Content Delivery Network) のオリジンなど、アクセス頻度が高く、すぐにデータが必要なもの。
- ポイント: データ保存の基本中の基本。迷ったらこれを選んでおけば間違いが少ないです。
2. S3 Intelligent-Tiering (S3 インテリジェント・ティアリング)
- 特徴: アクセスパターンを監視し、データアクセス頻度に応じて自動的に最適なストレージ層に移動してくれる賢いクラス。保存料金に加えて、監視と自動化の料金が少しだけかかります。
- こんなデータに: アクセス頻度が時間とともに変わるデータ、またはアクセスパターンが予測できないデータ。例えば、新規作成されたデータは頻繁にアクセスされるが、時間が経つとアクセスされなくなる可能性があるログファイルやユーザー生成コンテンツなど。
- ポイント: コスト最適化を自動で行いたい場合に非常に便利です。手動でライフサイクル設定を細かく調整する手間を省けます。
3. S3 Express One Zone (S3 エクスプレス・ワンゾーン)
- 特徴: 桁違いに速いパフォーマンスと低レイテンシを提供する新しいストレージクラス。ただし、データは1つのアベイラビリティーゾーンにのみ保存されます。
- こんなデータに: リアルタイム分析、機械学習のトレーニングデータ、高頻度でアクセスされるキャッシュデータなど、極めて高いアクセス性能と応答速度が求められるデータ。
- ポイント: 料金は他のクラスより高めですが、その分パフォーマンスは最高峰です。ただし、単一AZなので、AZ障害時の可用性を考慮する必要があります。
4. S3 Standard-IA (S3 標準-低頻度アクセス)
- 特徴: S3標準と同じく即座に取り出しが可能ですが、ストレージ料金が安く、データ取り出し料金がかかるクラス。
- こんなデータに: 月に数回程度しかアクセスしないバックアップデータ、災害復旧用のデータ、長期保存するが急に必要になる可能性があるログファイルなど。
- ポイント: アクセス頻度は低いけれど、いざという時に「すぐに」データが欲しい場合に最適です。最小ストレージ期間が30日間ある点に注意が必要です。
5. S3 One Zone-IA (S3 ワンゾーン-低頻度アクセス)
- 特徴: S3 Standard-IAよりもさらにストレージ料金が安いですが、データは1つのアベイラビリティーゾーンにのみ保存されます。
- こんなデータに: 再作成可能なセカンダリバックアップ、一時的なデータ、簡単に再生成できるログなど、万が一データが失われても影響が少ない、または再作成可能なアクセス頻度の低いデータ。
- ポイント: 最もストレージ料金を抑えたいが、ある程度のアクセス速度も必要な場合に検討されます。ただし、可用性は他の複数AZに保存されるクラスより低いです。
6. S3 Glacier Instant Retrieval (S3 Glacier インスタント・リトリーバル)
- 特徴: Glacierと名前についていますが、ミリ秒単位でデータを取り出せるアーカイブストレージ。Glacier Flexible Retrievalよりもストレージ料金は高いですが、取り出しが即座に行えます。
- こんなデータに: 年に数回しかアクセスしないが、アクセス時にはすぐに取り出す必要がある、規制要件のあるアーカイブデータ、メディア資産など。
- ポイント: Glacierシリーズの中で、「アーカイブ」かつ「即時アクセス」のニーズを両立したい場合に有力な選択肢です。
7. S3 Glacier Flexible Retrieval (旧 S3 Glacier)
- 特徴: 非常に低コストなストレージ料金ですが、データ取り出しに数分から数時間かかります。取り出しには「迅速」「標準」「一括」の3つのオプションがあります。
- こんなデータに: 長期的なデータバックアップ、コンプライアンス要件のあるアーカイブ、あまりアクセスしない履歴データなど、アクセス頻度が非常に低く、データ取り出しに時間がかかっても問題ないデータ。
- ポイント: 主にバックアップや長期アーカイブ目的で利用されます。取り出し速度とコストのバランスを選べます。
8. S3 Glacier Deep Archive (S3 Glacier ディープアーカイブ)
- 特徴: 最もストレージ料金が安く、超長期のデータ保存に特化したクラス。その分、データ取り出しに数時間から最長48時間と最も時間がかかります。
- こんなデータに: 法規制やコンプライアンスで何十年も保存が義務付けられているデータ、ほとんどアクセスされないが保存が必要なデータなど、アクセス頻度が極めて低く、取り出しに非常に時間がかかっても許容できる、超低コストのアーカイブデータ。
- ポイント: 「冬眠」させるような感覚で、データをとにかく安く、安全に、長期間保存したい場合に利用されます。
まとめとストレージクラス選択のヒント
各ストレージクラスにはそれぞれ得意な用途と料金体系があります。データがどんな使われ方をするのか、どれくらいの頻度でアクセスされるのかを考えて、最適なクラスを選びましょう。
簡単な選択のヒントを再掲します。
- 頻繁にアクセス: S3 Standard または S3 Express One Zone
- アクセスパターン不明: S3 Intelligent-Tiering
- 月1回程度のアクセス: S3 Standard-IA または S3 One Zone-IA
- 年数回のアクセス: S3 Glacier Instant Retrieval
- 長期アーカイブ: S3 Glacier Flexible Retrieval または S3 Glacier Deep Archive
どんなストレージクラスを使えばいいかの参考になればと思います。